The scope of this challenge is to predict the semantic alignment of a given general audio and text pair. In a generative model, evaluating the alignment between input and output is extremely important. For instance, in the evaluation of text-to-audio generation (TTA), methods have been proposed to evaluate the alignment between audio and text objectively. However, it has been pointed out that these methods often have a low correlation with human subjective evaluations. In this challenge, our goal is to build a model that automatically predicts the semantic alignment between audio and text for TTA evaluation. The aim is to develop a method for automatic evaluation that correlate highly with human subjective evaluations.
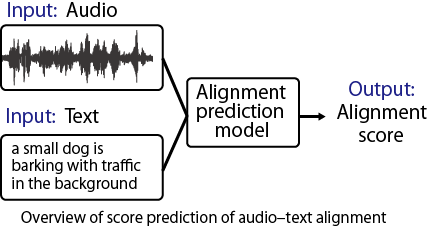
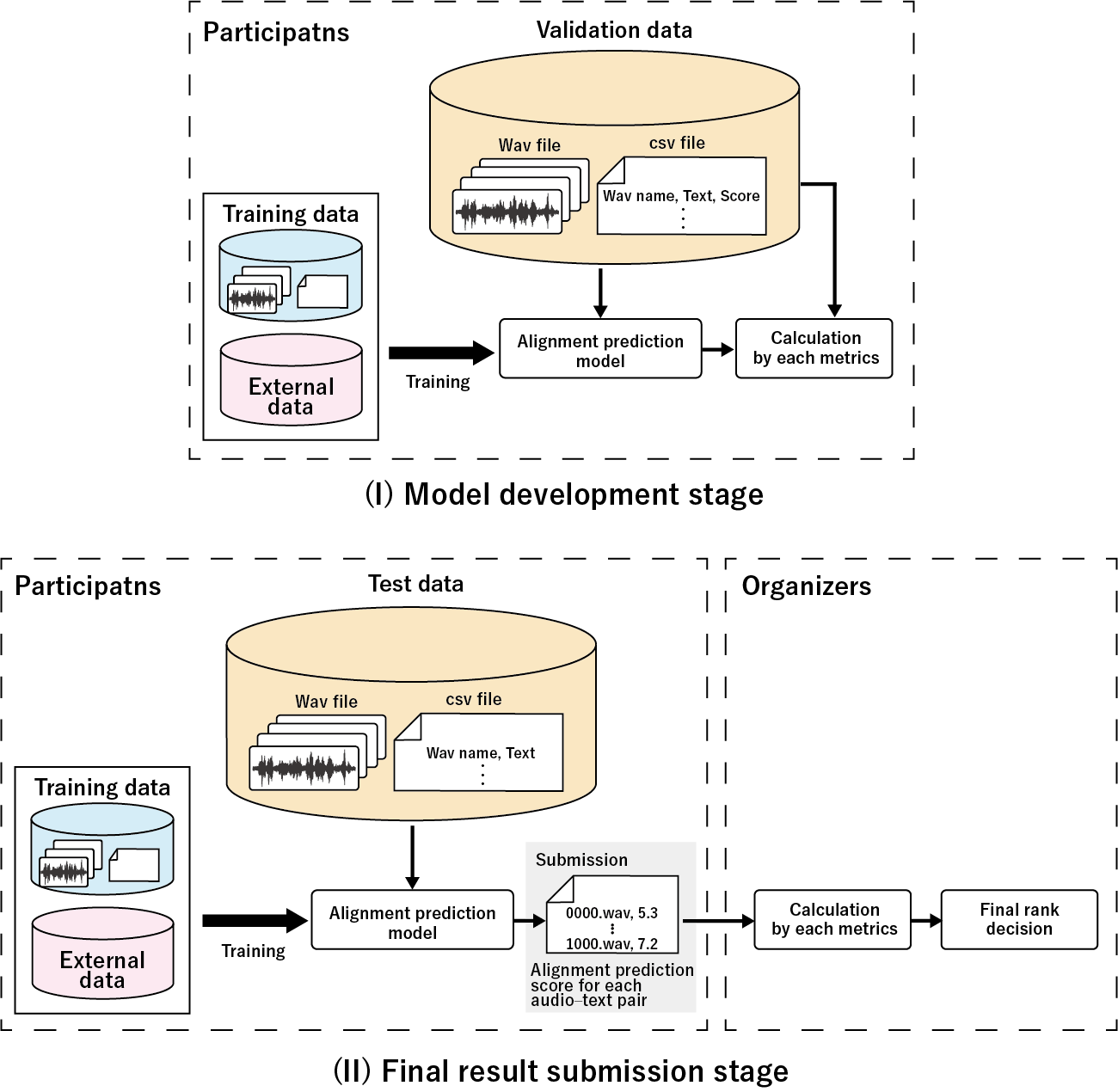
The training and validation data consist of the following:
The test data consist of 3,000 audio–text pairs. The listener ID is not included. The test data are evaluated by a set of listeners different from those for the training and validation data. The sampling rate, the number of channels, and the bit depth of audio correspond to those of audio in the training and validation data.
The datasets and models listed below can be used without the approval of the organizers.
| Dataset or model name ▲ ▼ | Type ▲ ▼ | Added ▲ ▼ | Link |
|---|
Submissions will be evaluated on the basis of the correlation coefficient and score error between predicted and average-semantic-alignment scores. Specifically, the metrics include the linear correlation coefficient (LCC), Spearman's rank correlation coefficient (SRCC), Kendall's rank correlation coefficient (KTAU), and mean squared error (MSE). When \(y\) represents the average-semantic-alignment scores and \(\hat{y}\) represents the predicted scores for each audio–text pair, the evaluation metrics are calculated as follows. \[ LCC = \frac{\sum(y - m_y)(\hat{y} - m_\hat{y})}{\sqrt{\sum(y-m_y)^2 \sum(\hat{y}-m_{\hat{y}})^2}}, \] where \(m_y\) and \(m_\hat{y}\) denote the mean of the vector \(y\) and \(\hat{y}\), respectively. \[ SRCC = 1 - \frac{6\sum d_i^2}{n(n^2 - 1)}, \] \[ d = rank(y) - rank(\hat{y}), \] where \(n\) and \(rank(\cdot)\) denote the number of sample and sorting by rank. If there are ties, the average rank is assigned to each of the tied values. \[ KTAU = \frac{N_c - N_d}{\sqrt{(N_c + N_d + N_{tx})(N_c + N_d + N_{ty})}}, \] where \(N_c\), \(N_d\), \(N_{tx}\), and \(N_{ty}\) denote the number of concordant pairs where the ranks of the predicted scores and average-semantic-alignment scores, discordant pairs, tied pairs for the x-axis variable, and tied pairs for the y-axis variable. \[ MSE = \frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2, \] where \(N\) denotes number of sample. The purpose of this challenge is to develop a method for automatic evaluation that correlates highly with human subjective evaluations. Therefore, we will use metrics that demonstrate correlations and differences from human evaluation scores. We will provide the source code for each evaluation metric on GitHub of the baseline model.
The final ranking is determined by the SRCC metric. If multiple teams are tied, the standings will be determined using the LCC, KTAU, and MSE metrics. The top five ranked submissions will be invited to submit a 2-page paper, with the accepted papers having the opportunity to be presented at ICASSP 2026.
The task organizers will provide a supervised score prediction model, similar to the baseline model of the RELATE. The baseline model consists of an audio encoder, text encoder, and an LSTM-based score predictor. A pre-trained model is used for both the audio and text encoders. Since this is the first challenge focusing on audio–text alignment, we have adopted a simpler baseline model. We will provide the source code of the baseline model on GitHub. If you use this code, cite the following papers.
For inquiries or questions, please send an email to contact@xacle.org.